Closed-vocabulary prediction
OPSNet is an omnipotent solution that maintains the SOTA performance on the training domain. We give a demo for training and prediction on COCO.
Open-vocabulary image segmentation is attracting increasing attention due to its critical applications in the real world. Traditional closed-vocabulary segmentation methods are not able to characterize novel objects, whereas several recent open-vocabulary attempts obtain unsatisfactory results, i.e., notable performance reduction on the closedvocabulary and massive demand for extra data. To this end, we propose OPSNet, an omnipotent and data-efficient framework for Open-vocabulary Panoptic Segmentation. Specifically, the exquisitely designed Embedding Modulation module, together with several meticulous components, enables adequate embedding enhancement and information exchange between the segmentation model and the visual-linguistic well-aligned CLIP encoder, resulting in superior segmentation performance under both open- and closed-vocabulary settings with much fewer need of additional data. Extensive experimental evaluations are conducted across multiple datasets (e.g., COCO, ADE20K, Cityscapes, and PascalContext) under various circumstances, where the proposed OPSNet achieves state-of-theart results, which demonstrates the effectiveness and generality of the proposed approach.
OPSNet is an omnipotent solution that maintains the SOTA performance on the training domain. We give a demo for training and prediction on COCO.
OPSNet also shows promising performance for cross-dataset evaluation. This demo shows the case of training COCO and making predictions on ADE20K.
We leverage the 21k categories in ImageNet to make open-vocabulary predictions. We could make prediction not only for plain 21k categories but also with hierachies like "Thing -> Animal -> Cat -> Siamese Cat".
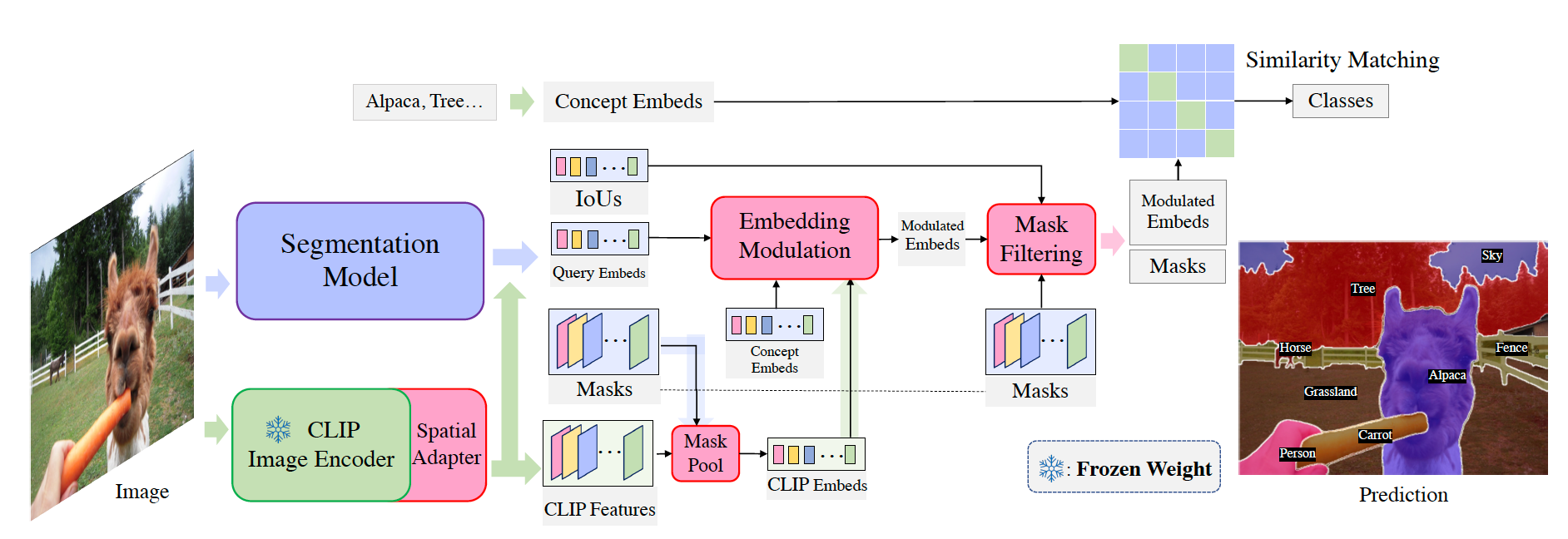
For an input image, the segmentation model predicts updated query embeddings, binary masks, and IoU scores. Meanwhile, we leverage a Spatial Adapter to extract CLIP visual features. We use these CLIP features to enhance the query embeddings and use binary masks to Mask Pool them into CLIP embeddings. Afterward, the CLIP Embed, Query Embeds, and Concept Embeds are fed into the Embedding Modulation module to produce the modulated embeddings. Next, we use Mask Filtering to remove low-quality proposals thus getting masks and embeddings for each object. Finally, we use the modulated embeddings to match the text embeddings extracted by the CLIP text encoder and assign a category label for each mask.
@article{chen2023open,
title={Open-vocabulary Panoptic Segmentation with Embedding Modulation},
author={Chen, Xi and Li, Shuang and Lim, Ser-Nam and Torralba, Antonio and Zhao, Hengshuang},
journal={arXiv preprint arXiv:2303.11324},
year={2023}
}